

前些天的文章里不少人觉得关于处理器核心数量和游戏之间关系这个话题比较有意思,但或许你心里也有这样的疑问:究竟当代游戏对多线程有多么的不依赖?空口无凭,用软件跑一跑处理器占用率来试试吧。
小胖选择了文明6、最终幻想15、刺客信条起源这三款玩家应该都不少的游戏(其实我是想多跑几个游戏的,但我们的华硕FX80在跑了这三个之后,无论如何都无法再稳定运行测试程序,只好作罢,当然,这只是调侃,不一定是笔记本的问题),其中文明6、刺客信条起源坊间传闻对处理器要求很高,而在AMD新Ryzen处理器的测试里,刺客信条起源的核心利用率似乎也相当给力,那到底在i7 8750H这种6核12线程游戏里,它们的表现是有多厉害呢?一款款来分析吧:
文明6,在小胖之前的测试里它的确算是多核心优化很好的一款游戏,从2到4,再从4到6也都有相应的提升,但性能提升幅度并没有与核心数量的增加呈线性关系,这说明优化并没与想象中那么好,实际上它在Benchmark中的负载如下:
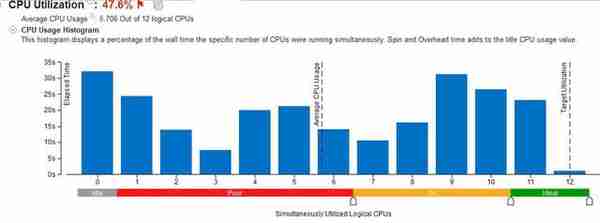
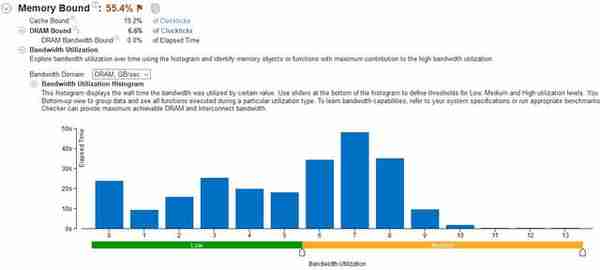
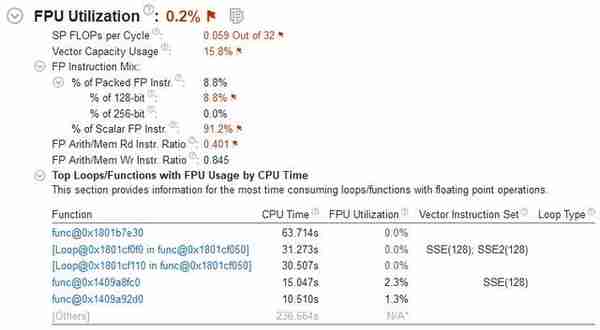
图1:柱状图横轴表示线程数量,0就是空载,12就是6核12线程全负载。纵轴是负载时间,可以看到在文明6的243秒测试里,负载时间最长的是9-10线程,也就是4-5核,总计57秒左右。12线程全满的时间几乎可以忽视(1.18秒)。
图2:内存绑定度总体高,但对多通道并不太敏感,内存吞吐多在7~8GB/s,测试用的单条8GB DDR4-2666勉强够用。
图3:向量指令利用率低,只有15.8%,主要也还是128bit的SSE,说明在文明6对8750H能提供的指令集并没有特别感兴趣。反倒是SISD(单指令单数据流)的标量指令占用率很高,多线程优化的方式看来是比较简单粗暴。
接下来是刺客信条起源,使用的依然是内置Benchmark:
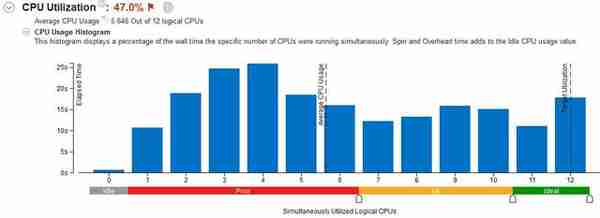

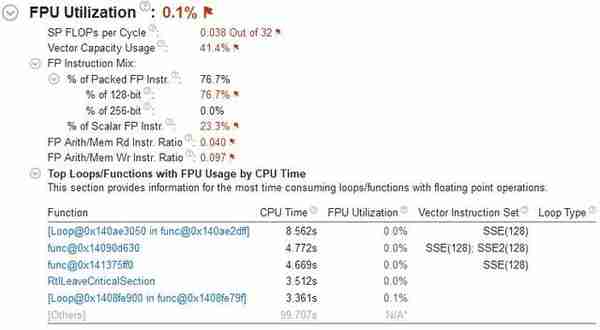
图1:200秒的测试里,2~4线程占了50秒,9~12线程总计时间60秒,走势很平,从这方面来看刺客信条起源也并不算一款多线程优化特别好的游戏。
图2:内存绑定度更高了,单通道已经成为瓶颈被标红,内存吞吐量达到12GB/s以上
图3:处理器的向量指令集使用率增加了,刺客信条起源的处理器指令优化相对要更现代一点。

但如果是使用AMD Ryzen 5 2600X测试刺客信条起源benchmark,可以用尽6核12线程(如上图),成绩惊人,但这里其实是有作弊嫌疑的,因为在正常游戏而非benchmark中,8核并不会比6核甚至4核来得更有优势。这主要因为Benchmark的场景是固定编程,只要做好先期优化,分支预测命中率非常高,逻辑单元可以完全发挥性能。
其实这也是处理器很难在游戏中发挥多线程的原因之一,毕竟一个数学教授做8道题的速度不一定会比8个中学生同时做8道题慢,因为预测、解码、回写、指令发送、I/O等等都需要精细度很高的优化,很容易前一发动全身,一步走错全盘打乱……再加上游戏公司哪有那么多工夫做线程优化,跳票了谁负责?所以大多都只是做了个基本的多线程优化差不多就行了,而且随着核心数量越多,优化就越困难。对于游戏而言最重要的秘诀其实英特尔已经告诉你了:狂刷单双四核睿频,现阶段这思路无疑是正确的。
AMD取了个巧,只在刺客信条起源这么短短不到3分钟的Benchmark里做了多核优化,所以跑出来成绩上了天,但对实际游戏却没有意义。
GPU不同,作为非常纯粹的SIMD丛集,要做的工作就是最简单粗暴的并行计算——这自然需要堆积多内核。游戏最重要的画面渲染是由GPU完成,而这个过程也是游戏研发的核心之一,所以GPU在游戏中权重更高。玩游戏第一是看GPU,CPU方面只要保证四核,睿频够高就OK!
第三个游戏:最终幻想15。之前小胖测了它其实四核成绩最好,但缺乏数据解读,那么接下来就是:
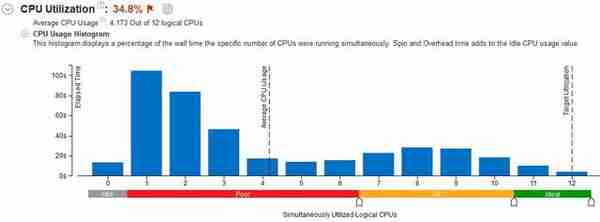
图1:因为跑的是Benchmark版,所以其实它不需要经历前面两款“进游戏、打开Benchmark”的这段闲置过程,直接跑的就是测试全程,可以看到处理器数量的占用率是非常低的,410秒的测试里足足有近200秒是双线程在跑,3线程有46秒,除此之外最多的就是8线程的28秒了,换句话说最终幻想15就是不折不扣的频率大过天。
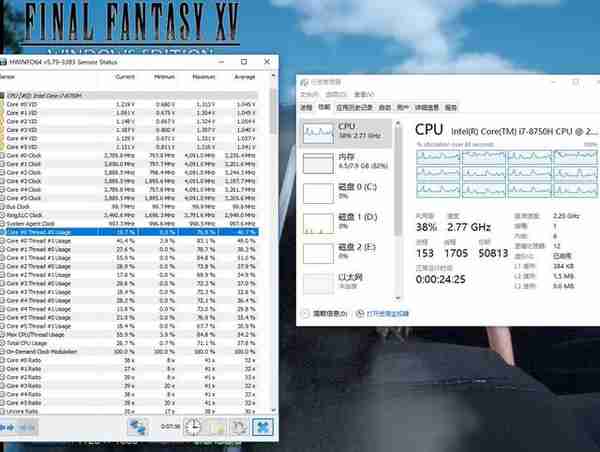
这儿还可以简单说说测试软件的问题:因为任务管理器或HWinfo等软件只能读取线程占用率,打开它们看到的是全部线程都在工作,只是幅度不同。但这是在整个Windows系统下的负载,无法分析具体的游戏应用里主要负载计算工作的线程数有多少,也没有办法查到它所使用的具体指令集,因此只看这些软件是无法获知正确信息的。
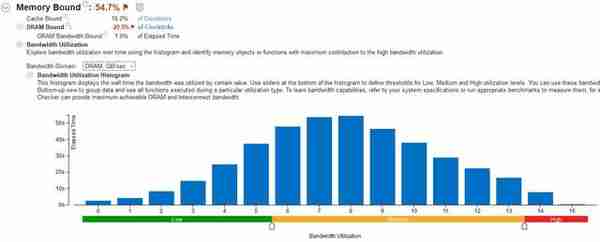
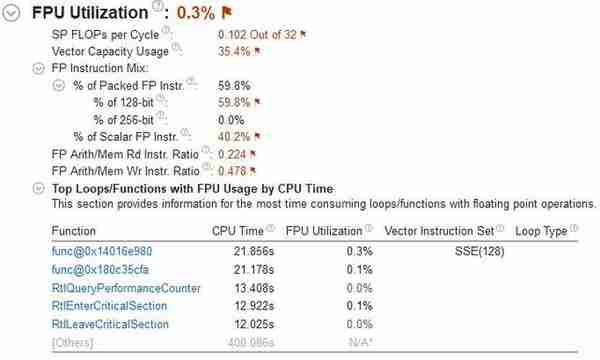
图2:最终幻想15的内存绑定呈山脊状,分布比较均匀,但8GB内存显然还是拖了后腿,尽量上更大容量更多通道吧。
图3:向量指令使用率尚可,作为主机移植大作,最终幻想15的优化策略其实依然可以看出主机思维——少数线程高频刷整数、单精度浮点最大化。
虽然没有列举一些最新的例子,比如远哭5之类的,但结果应该也都差不多,这些游戏对CPU的优化方向,与CPU自身的发展方向存在差异,所以多核很难在游戏中真正体现出与规模增长相对应的性能增幅。
此前也提到了Cinebench,R15虽然是最新版,但实际上也是很久都没更新了,因为有CPU渲染测试,所以经常被各种媒体视为评判处理器性能高下的核心成绩,实际看看它的CPU和内存占用:
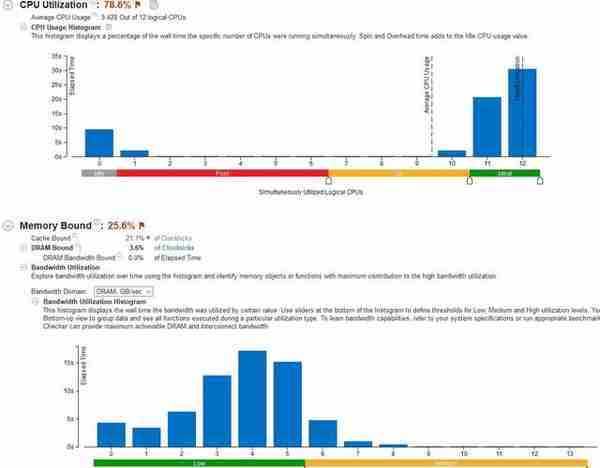
首先,确实可以让8750H的11~12个线程基本跑满,所以在负载调用上是没问题的。但它的缓存绑定却存在一定的问题,L2\L3有大量时钟都处于等待取回数据的挂起状态,这有一种可能就是Cinebench R15的测试数据块偏大,指令步长又偏长,已经接近缓存本身大小(L2=6X256KB,L3=6X1.5MB),因为共用寄存器,所以数据块和指令形成空间冲突,需要调用更低级别的存储单元,形成性能浪费……
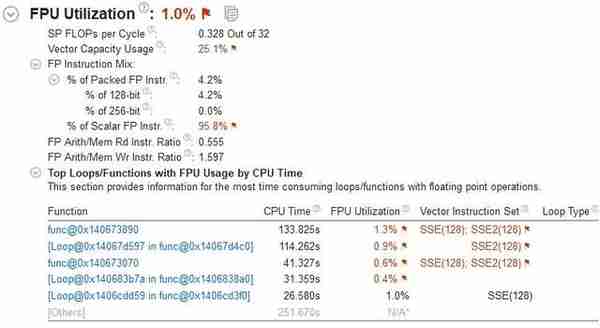
Cinebench R15的处理器测试只调用了25.1%的向量指令,而且主要是128bit的SSE,标量倒是上到了95.8%,这说明它的测试方法比较老,让新指令集无处发挥。
那么能用到新指令集的测试程序有哪些呢?简单介绍一个:y-cruncher,支持多线程和最新指令集的圆周率计算器。它的数据量非常大,10亿位小数点的计算需要4.81GB的空闲内存,我跑了5亿位的测试,核心占有率和内存吞吐如下:

单通道8GB内存还是太捉急了,但基本能用尽11~12线程,所以跟R15一样至少是可以让全部核心真正忙起来的。但都是忙起来,用的工具不同自然性能表现不同,对于英特尔处理器来说,y-cruncher的意义在于向量指令的利用率:
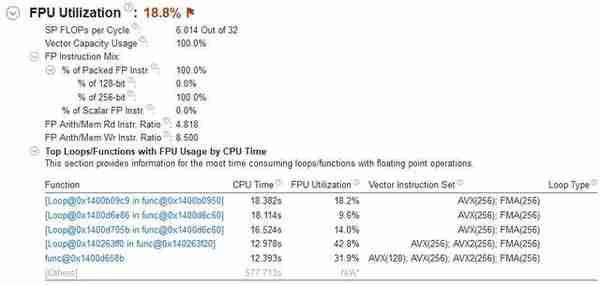
100%!而且全是256位AVX和FMA,2.2~2.4GHz运行的8750H加单通道8GB DDR4-2666内存,5亿位的成绩是66.79秒,这个频率说实话发挥不出8750H的全部实力,但也比较有代表性了。4核8线程,2.9GHz的至强E3-1535M v5搭配16GB内存参考成绩是56.56秒左右。
总结:衡量性能没有统一的标准,即便是对于GPU来说,游戏也是更看重单精度浮点,这是当年Maxwell砍双精度提单精度的原因,而科学计算就更需要双精度,深度学习甚至有用到半精度。虽然游戏性能一贯是NVIDIA领先,但如果论挖矿,峰值浮点和Hash性能AMD又可以超越NVIDIA。所以只用一个R15就决定处理器性能高低?这种说法显然是不负责的。
对于当下,甚至可以说是未来很长一段时间的PC游戏来说,多核都无法直接转化为帧速上的优势,一则GPU才是决定帧速的核心;二则多线程优化的时间、人力、经济成本都太高,顶多是固定渲染的Benchmark优化一下,正常游戏里满打满算就是四核优化,未来也很难会发生改变。不过现在的多核处理器也伴随高睿频而来,比如8750H的双核在游戏中可跑到近4GHz,四核也能接近3.9GHz,这是7700HQ不能比的,所以在散热不是问题的前提下,频率可以高数值稳定才是选8代的理由,如果单纯按核心就说49年入国军的话,那今年咱们都别买了,因为英特尔8核就要来了,但看完本文的你还会这样想么?
PS:游戏之外的日常应用,6个以上的核心也不会有特别大的作用,但如果有同时多开应用程序、视频渲染、RAW照片后期、各类工科设计需求,那多核还是有用的。
